When post-hardcore emo band Silverstein approached our Berlin-based art collective about a collab, AI emo seemed like a perfectly ironic thing to make exist.
After training raw audio neural nets on the music of Silverstein, generating days worth of music, curating my favorites, and organizing them with annotations, the result is an album of 1000 songs over 26 hours long …
..about absolutely nothing. There are no lyrics. It’s just random syllables and raw sound. There’s something really appealing to me about this.

Most songs are fast & loud. Some are soft, acoustic, ambient, glitchy, or utterly weird. Some have screams, some have harmonies, some have both. Some start calm and build up to epic proportions. Some go into an unusual time signature like 5/4. And I listened through them all. Twice 👀

Curating
Very rarely does a neural net create listenable music 100% of the time. Often the listenability rate is ~10% and we need to do heavy curation before releasing any of it. To bring out the best in the music, I spent months tuning hyperparameters, running ~100 experiments, eventually ending up with models of relatively high listenability. Roughly ~70 hours worth of music were generated.
Curating was going to be a long process, so I made a tool to help me do it more quickly. Many songs I could tell from looking at the spectrogram were not gonna make it. The rest I had to listen. Some had too much silence. Some sounded too much like a bad quality live bootleg. But some of those strange ones were actually really interesting to listen to and I kept them. I was able to throw out 2/3rds, narrowing them down to my favorite 1k songs.

Simultaneously I used this tool to annotate the style of the song, tap out the tempo, and take note of any distinctions within each song:
Examples of distinctions
doom riff, breakdown in 6/8, metal riff, cool drums, siamese songs, thrash riff, triplet transition, swing beat, slide, train horn, 5/4 time signature, slide riff, blues riff, ambient outro, cool riff, rising screams, 5/4 triplet riff, noisy, hellbeast solo, bass slide, textural intro, dirt riff, dissonance, long scream, flatline, hangs up, pinch harmonic, ghosts, stutter beat, dbeat, no singing, 2 step riff, groovy riff, evil riff, guitar slide, rap, chaotic, experimental, feedback, chugs, drums intro, 3/4 riff, guitar lick, 6/8 riff, doublekick, breakdown, negative space, audience, blastbeat, drone, guitar solo, …
Tempo
I obsessed hard over paulbot’s playing, tapping out the BPM to every song until the idea of BPM became totally meaningless:
“Does this dbeat count as 120bpm or 240bpm?”
Dbeats are awesome like that. There’s this Escher like quality to the sense of pulse. If you speed up a 180bpm drum’n’bass rhythm 2x, you get a dbeat that feels like 180bpm, and there’s an ambiguous moment in between where the tempo appears to cut in half. I realized just how nebulous BPM is. I think tempo is more of a spectrum. The same is true for pitch and harmony — only the pitch of a sine wave is unambiguous.
Ambient songs without rhythm have zero tempo, and heavier songs with a strong blast beat have the fastest tempo.
Temperature
Temperature is a parameter that modifies how the generator samples from its probability distribution at each time step. Temperatures in this collection range from 0.98 to 1.02. Even within that seemingly small range you can hear a world of difference:
>1.0 high temperature = noisier predictions, more surprises, more high frequencies / cymbals, faster tempos.
=1.0 temperature = the statistics the model learned (in theory, most closely matches the training dataset)
<1.0 low temperature = overconfident predictions (fewer surprises, slower tempos, acts as a noise reduction technique, but at the risk of collapsing into silence or getting stuck in one thing).
Learn more about how temperature affects neural audio synthesis here
Visualizer
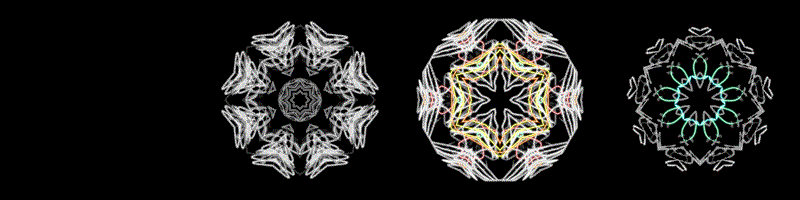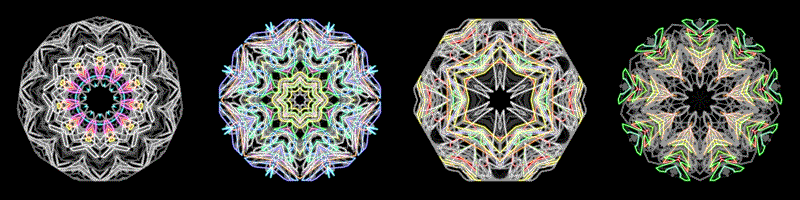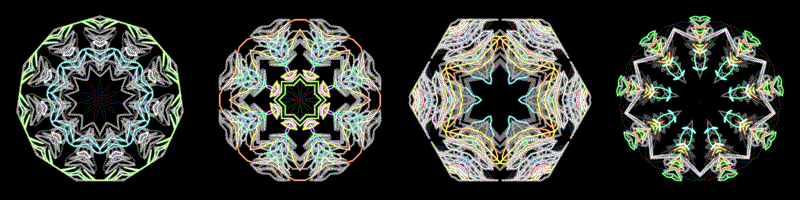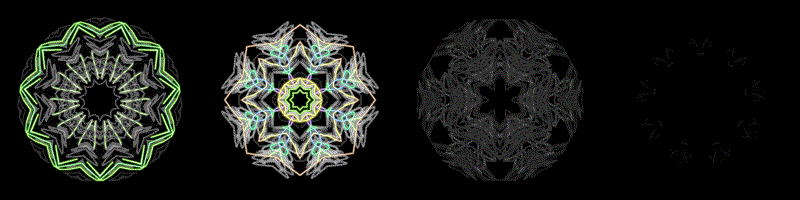
These are what feelings look like 😐
The thumbnail GIFs are a timelapse of the full video. You can see which songs start loud and chill out, or start quiet and build up.
To generate the visuals, I made a custom algorithm based on harmonic-percussive source separation, a spectral decomposition method by Driedger et al which I helped implement in librosa.
I split the spectrograms into percussion and harmony using a median filter (percussion = horizontal components, harmony = vertical components), with a margin to remove noise (the residual left over). I re-analyze the harmony component with a Constant-Q transform, so that each frequency bin aligns to the 12 pitches. I can map the pitches to color, where C = red, C# = red-orange, etc.
By isolating the percussion component from noise and harmony, we can exaggerate abrupt changes. I re-analyze the percussion component as a Mel Frequency Spectrogram, where frequencies ranges are perceived as timbrally equidistant. Since each frequency range has a different perceived loudness (e.g. mids are the loudest), I adjust the loudness in each bin according to A-weighting (a perceptual weighting scheme). I convert magnitude to decibels, which is how we perceive the degree of loudness, and map this to brightness.
I also have a “stickiness” where the frequencies decay from their recent maximum. This coincides with our working memory of recent percussive events, exaggerating the most salient events, and reducing the noise from less salient events.
To render all the videos in a day, I rented 1024 CPUs on AWS and GCP. My screen looked like this:
Song Titles
Song titles were generated to be synonyms of “Fake Feelings” that preserve some amount of alliteration. For example:
disreputable discomfort
mock melancholy
bootleg abasement
archetypal angst
deceptive sadness
The Fingerprint Test
Sometimes generative models overfit. Overfitting is when a model memorizes parts of its training data and spits them back verbatim. This can be cool as a remix/sampling technique. However, we want to avoid this when we’re aiming to generate new original music.
Training a generative network only part of the way is one way to prevent it from fully memorizing the data. There’s a sweet spot between learning too little and too much where the model is its most creative. Also, regularization techniques like dropout help.
We can test for overfitting by using an audio fingerprinting service like Pex, Shazaam, or Content ID. We ran our songs through Pex’s engine, which searches for copies throughout all label catalogues, all of YouTube, Soundcloud, etc. It even detects cover songs. (Zack from Dadabots is head of machine learning at Pex, and tells me it’s the most accurate fingerprinter used by major labels).
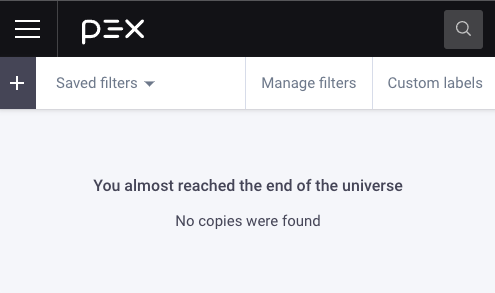
Pex returned zero! No sampling. No overfitting. No covers. It didn’t even get copyright flags from Silverstein’s own discography. It means these songs are sufficiently original.
In comparison, our experimental Battles album, which clearly overfits, was flagged by Pex within 10 minutes of searching. It’s hard to tell ahead of time if a model is going to overfit, or if certain settings (e.g. low temperature?) lead to more overfitting. Fingerprinting the outputs is a quick way to validate.
Fingerprinting could become standard practice for AI music projects seeking to create original music, and validating that they did so.
License
These songs are licensed CC-BY-NC. They’re free to share and remix, for non-commercial use. If you want to use yours commercially, ask Silverstein directly, or reach out through Dadabots and we can put you in touch.
Flesh on a Skeleton
Listening to all the outputs, I appreciated how the distribution of style roughly matched the distribution of the dataset. This is a nice feature of likelihood-based sequence models. Whereas adversarial models, on their own, risk suffering from mode collapse (sticking too much to one thing without capturing the diversity). However, adversarial losses are great at improving realism. Parallelizable convolutional layers, trained adversarially, are particularly fast. They seem to work well as an upsampling layer, but I still don’t think they beat out causal, autoregressively-generated sequence layers in music composition quality. The freedom to wander, timestep to timestep, creates cool transitions and melodies that just don’t happen otherwise. I find that conditioning adversarially-trained layers on the outputs of likelihood-trained layers seems to deliver the best of both worlds, like flesh on a skeleton. This is still an active area of research for us, and we will publish more on it in the future.
Dadabots
We started in 2012 as a hackathon team at MIT making Soundcloud bots with echonest-remix and librosa, but it wasn’t until 2015 that Gene Kogan’s work inspired us to quit our jobs and self-study deep learning. Since then we’ve been publishing research on our methods for creating music with raw audio neural nets, collaborating directly with bands, and making 24/7 livestreams.
Today we release this project on Gene’s BrainDrops.
The karmic loop is complete! ⟳
Punk and Metal
Certain music genres do better with AI. Hardcore punk, math metal, tech death, and free jazz work well as training data. More than being just an ersatz imitation, neural synthesis seems to contribute something new & interesting to these styles.
The reasons, we believe:
- They use a limited range of timbres/instruments, with a wide variety of patterns. This seems to help with training.
- Noise and chaos are part of these styles’ aesthetic.
- Metal pairs well with human elimination 😈..jk
Our first experiments with punk models used NOFX — the outcome was hilarious.
Read more about our process here: Generating Albums with SampleRNN to Imitate Metal, Rock, and Punk Bands.
Trying Not To Fuck Up The Environment
Ethereum has become an energy suck, and will be until its v2.0 upgrade. We used this calculator to estimate this project’s share of responsibility of the network’s emissions, and offset 8x that amount in carbon credits, which supports carbon reduction initiatives. Check out this guide on eco-friendly NFTs. Death to PoW 💀
Thank You
Hi, we’re Dadabots. We also develop audio synthesis based on trinary CPUs and quantum circuits, and get in trouble for deep fakes.
Patrons of Dadabots, thank you 🙏 Revenue from drops funds our scientific research and invention of new forms of music synthesis.
Stay tuned for more.
Follow us on twitter @dadabots
Join our discord
Subscribe on YouTube
